Different Computer Vision Tasks
The area of Computer Vision basically deals with anything that humans see and perceive.
There are so many tasks that we humans do almost subconsciously that we hardly think are even worth mentioning. However, for a computer to learn to perform or even try to mimic such things are very difficult.
Imagine looking outside your window. What do you see? Maybe you are sitting in an office building and see traffic outside. Maybe you are on a vacation and see a beach or mountains or a forest outside. Do you ever wonder how you recognize something or someone? How do you know when you look at someone and know who they are?
Subconsciously, we first identify objects in any image that we see. Then we try to find what relations exist between objects to identify the scenery or a place. Only then do we get an idea of what is happening in the image. Sometimes, we also look at an incomplete image and use our knowledge and experience to determine what is missing from it. All of these are Computer Vision tasks.
The article briefly explains the following Computer Vision tasks:
- Object Detection
- Image Classification
- Visual Relationship Detection
- Image Captioning
- Image Reconstruction or Image Inpainting
- Face Recognition
- Instance Segmentation
- Semantic Segmentation
Let’s get started!
Object Detection is the ability to detect or identify objects in any given image correctly along with their spatial position in the given image, in the form of rectangular boxes (known as Bounding Boxes) which bound the object within it. An example is shown below which detects objects such as laptop, glasses, notebook, coffee and iphone in their Bounding Boxes.

Another computer vision task which is pretty popular is Image Classification. Image Classification basically means identifying what class the object belongs to. For example, in the image shown below, there are objects present belonging to various classes such as trees, huts, giraffe, etc. The machine or deep learning model would determine that the animal detected in the image belongs to class giraffe with the highest probability.

Visual Relationship Detection is another Computer Vision task. It is the ability to decipher what relationship does the two objects share. For example, look at the image below. Here the relationship is “plays”, the subject is “man” and object is “guitar”.
In Computer Vision, usually a relationship is defined in the form of a triplet <Subject, Predicate, Object> . So the picture below would be described as <“man”, “plays”, “guitar”>.

Image Captioning is looking at an image and describing what is happening in the image. The image given below contains annotations or labels which describe what is happening in the Image which should give you a good idea about what Image Captioning does.

Image Reconstruction or Image Inpainting is the ability to identify what is missing in an image in order to reconstruct it. The image given below shows examples where parts of an image has been damaged for some reason and the task is to recreate and fill the image to reconstruct the original image.


Another interesting computer vision task is Face Recognition. Have you ever wondered how do you recognize famous figures in reality when you only have ever seen their images and videos online? That is because we are capable of face recognition. If we ever see someone’s image, we are capable of identifying him or her in any image, video or live meet. Anyone who looks at the image below knows this is Brad Pitt. This is an example of facial recognition.

Next, let’s talk about another hot topic of research in the area of Computer Vision namely, Instance Segmentation. Instance Segmentation basically identify different instances given in the image with their boundaries intact. For example, the image below showcases that the model has tried to identify each object instance in the image and recognized their boundary at the deep pixel level.

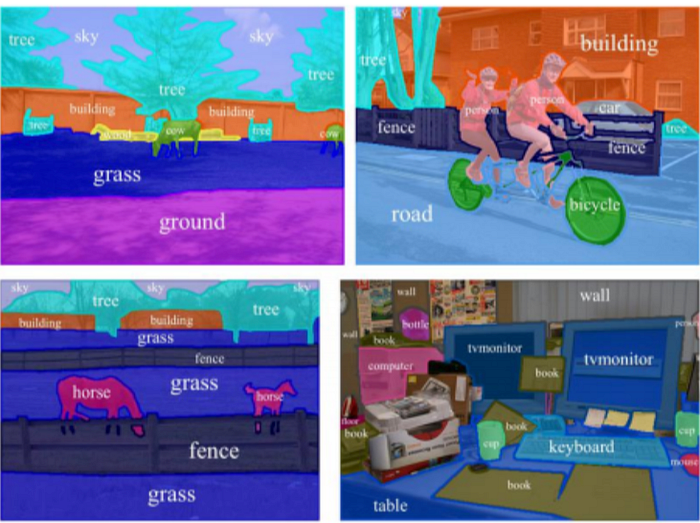
Last but not the least, let’s talk about Semantic Segmentation. Semantic Segmentation basically tries to identify similar objects in the object which belong to the same class at the pixel level. For example, the image below showcases that the model has tried to identify similar objects like trees, tires in the bicycle, grass, buildings etc and color coded them in same color to symbolize them belonging to same class.
Many times we get confused between the concepts of Image Classification, Object Detection, Instance Segmentation and Semantic Segmentation. The picture below helps us understand the difference better.

In the upper left, we see that classification implies that this picture or image contains objects of class balloon.
In the lower left, we see that Object detection means not only classifying objects in their correct classes but also having an idea about their spatial position in the picture.
In the upper right, we see that Semantic Segmentation implies that we understand that all objects in the image are balloons and should constitute same class.
Last but not the least, the image in the lower right corner shows Instance Segmentation which implies that we identify not just objects or instances and their spatial locations but also their pixel level boundaries.
I hope this post helps you understand the idea underneath these tasks.
There are many computer vision tasks which exist in the world. This is just a brief overview of few of the most popular computer vision tasks in the world.
Thank you!
